Пагинация сайта - хитрый оборотень. Он используется в контекстах, начиная от отображения элементов на страницах категорий и заканчивая архивами статей, слайд-шоу галереи и темами форума.
Для профессионалов SEO вопрос не в том , придется ли вам иметь дело с нумерацией страниц, а в том, когда.
В определенный момент роста веб-сайтам необходимо разделить контент на ряд составляющих страниц для взаимодействия с пользователем (UX).
Наша работа состоит в том, чтобы помочь поисковым системам сканировать и понимать взаимосвязь между этими URL-адресами, чтобы они индексировали наиболее релевантную страницу.
Со временем лучшие практики SEO по обработке страниц эволюционировали. Попутно многие мифы выдавали себя за факты. Но уже нет.
В этой статье мы расскажем о том, что:
- Развенчайте мифы о том, как нумерация страниц вредит SEO.
- Представьте оптимальный способ управления нумерацией страниц.
- Обзор неправильно понятых или некачественных методов обработки нумерации страниц.
- Узнайте, как отслеживать влияние разбиения на страницы ключевых показателей эффективности.
Как нумерация страниц может повредить SEO Вы, наверное, читали, что нумерация страниц вредна для SEO
.
Однако в большинстве случаев это связано с отсутствием правильной обработки пагинации, а не с существованием самой пагинации.
Давайте посмотрим на предполагаемое зло нумерации страниц и на то, как преодолеть проблемы SEO, которые она может вызвать.
Разбиение на страницы приводит к дублированию содержимого
Исправляйте, если нумерация страниц была реализована неправильно, например, при наличии страницы «Просмотреть все» и страниц с разбивкой на страницы без правильного rel=canonical или если вы создали page=1 в дополнение к корневой странице.
Неверно, когда у вас оптимизированная для SEO нумерация страниц. Даже если ваши теги H1 и метатеги одинаковы, фактическое содержимое страницы отличается. Так что это не дублирование.
Да, это нормально. Полезно получить отзывы о повторяющихся заголовках и описаниях, если вы случайно используете их на совершенно разных страницах, но для серий с разбивкой на страницы это нормально и ожидается использовать то же самое.
— 🍌 Джон 🍌 (@JohnMu) 13 марта 2018
г. Нумерация страниц создает тонкий контент
Исправьте, если вы разделили статью или фотогалерею на несколько страниц (чтобы увеличить доход от рекламы за счет увеличения просмотров страниц), оставив слишком мало контента на каждой странице.
Неверно, когда вы ставите желания пользователя легко потреблять ваш контент выше доходов от баннерной рекламы или искусственно завышенных просмотров страниц. Разместите UX-дружественное количество контента на каждой странице.
Нумерация страниц разбавляет правильные сигналы
ранжирования. Пагинация приводит к тому, что внутренние ссылки и другие сигналы ранжирования, такие как обратные ссылки и социальные сети, распределяются по страницам.
Но может быть сведен к минимуму с помощью нумерации страниц только в тех случаях, когда одностраничный подход к контенту может привести к ухудшению взаимодействия с пользователем (например, страницы категорий электронной коммерции). И на таких страницах, добавляя как можно больше элементов, не замедляя страницу до заметного уровня, уменьшить количество страниц с разбивкой на страницы.
При разбиении на страницы используется бюджет сканирования
Корректируйте, если вы разрешаете Google сканировать страницы с разбивкой на страницы. И есть некоторые случаи, когда вы хотели бы использовать этот бюджет.
Например, чтобы робот Googlebot перемещался по URL-адресам с разбивкой на страницы, чтобы перейти к более глубоким страницам контента.
Часто некорректно, когда вы устанавливаете в Google Search Console обработку параметра пагинации на «Не сканировать» или устанавливаете роботов.txt запрещают, в случае, если вы хотите сэкономить свой бюджет сканирования для более важных страниц.
Управление нумерацией страниц в соответствии с рекомендациями
SEO Используйте сканируемые якорные ссылки Чтобы поисковые системы могли эффективно сканировать страницы с разбивкой на страницы, сайт должен иметь якорные ссылки

с атрибутами href для этих URL-адресов с разбивкой на страницы.
Убедитесь, что ваш сайт использует <a href="your-paginated-url-here"> для внутренних ссылок на страницы с разбивкой на страницы. Не загружайте якорные ссылки с разбивкой на страницы или атрибут href через JavaScript.
Кроме того, необходимо указать связь между URL-адресами компонентов в серии с разбивкой на страницы с помощью атрибутов rel="next" и rel="prev".
Да, даже после печально известного твита Google о том, что они больше не используют эти атрибуты ссылок вообще.
Генеральная уборка!
Когда мы оценили наши сигналы индексации, мы решили отказаться от rel=prev/next.
Исследования показывают, что пользователи любят одностраничный контент, стремитесь к этому, когда это возможно, но многокомпонентный контент также подходит для поиска Google. Знайте и делайте то, что лучше для *ваших* пользователей! #springiscoming pic.twitter.com/hCODPoKgKp— Google Webmasters (@googlewmc) 21 марта 2019 г.
Вскоре после этого Илья Григорик уточнил, что rel="next" / "prev" все еще может быть ценным.
Нет, используйте нумерацию страниц. Позвольте мне переосмыслить это. Робот Googlebot достаточно умен, чтобы найти вашу следующую страницу, посмотрев ссылки на странице, нам не нужен явный сигнал «предыдущий, следующий». И да, есть и другие веские причины (например, A11y), по которым вы можете захотеть или должны добавить их еще.
— Илья Григорик (@igrigorik) 22 марта 2019
г. Google — не единственная поисковая система в городе. Вот взгляд Bing на этот вопрос.
Мы используем rel prev/next (как и большую часть разметки) в качестве подсказок для обнаружения страниц и понимания структуры сайта. На этом этапе мы не объединяем страницы вместе в индексе на их основе и не используем предыдущий/следующий в модели ранжирования.
https://t.co/ZwbSZkn3Jf— Фредерик Дюбю (@CoperniX) 21 марта 2019
г. Дополните rel="next" / "prev" самоссылающейся ссылкой rel="canonical". Таким образом, /category?page=4 должен rel="canonical" в /category?page=4.
Это уместно, так как разбиение на страницы изменяет содержимое страницы, а также главную копию этой страницы.
Если URL-адрес имеет дополнительные параметры, включите их в ссылки rel="prev" / "next", но не включайте их в rel="canonical".
Например:
<link rel="next" href="https://www.example.com/category?page=2&order=newest" />
<link rel="canonical" href="https://www.example.com/category?page=2" />
Это укажет на четкую взаимосвязь между страницами и предотвратит возможность дублирования контента.
Распространенные ошибки, которых следует избегать:
- Размещение атрибутов ссылки в контенте
<body>. Они поддерживаются только поисковыми<head>системами в разделе вашего HTML. - Добавление ссылки rel="prev" на первую страницу (также известную как корневая страница) в серии или ссылку rel="next" на последнюю. Для всех остальных страниц в цепочке должны присутствовать оба атрибута ссылки.
- Остерегайтесь канонического URL-адреса корневой страницы. Скорее всего, на ?page=2, rel=prev должен ссылаться на канонический, а не ?page=1.
Код <head> четырехстраничной серии будет выглядеть примерно так:
- Один тег нумерации страниц на корневой странице, указывающий на следующую страницу в серии.
<link rel="next" href="https://www.example.com/category?page=2″><link rel="canonical" href="https://www.example.com/category">
<link rel="prev" href="https://www.example.com/category"><link rel="next" href="https://www.example.com/category?page=3″><link rel="canonical" href="https://www.example.com/category?page=2">
<link rel="prev" href="https://www.example.com/category?page=2″><link rel="next" href="https://www.example.com/category?page=4″><link rel="canonical" href="https://www.example.com/category?page=3">
<link rel="prev" href="https://www.example.com/category?page=3"><link rel="canonical" href="https://www.example.com/category?page=4">
Джон Мюллер
прокомментировал: «Мы не относимся к нумерации страниц по-другому. Мы относимся к ним как к обычным страницам».
Это означает, что страницы с разбивкой на страницы не распознаются Google как серия страниц, объединенных в один фрагмент контента, как они рекомендовали ранее. Каждая страница с разбивкой на страницы имеет право конкурировать с корневой страницей за ранжирование.
Чтобы побудить Google вернуть корневую страницу в поисковую выдачу и предотвратить появление предупреждений «Повторяющиеся метаописания» или «Повторяющиеся теги заголовков» в Google Search Console, внесите простые изменения в свой код.
Если корневая страница имеет формулу:Последовательные страницы с разбивкой на страницы могут иметь формулу:


Эти заголовки страниц URL с разбивкой на страницы и мета-описание намеренно неоптимальны, чтобы отговорить Google от отображения этих результатов, а не корневой страницы.
Если даже с такими изменениями страницы с разбивкой на страницы ранжируются в поисковой выдаче, попробуйте другие традиционные тактики SEO на странице, такие как:
- Деоптимизируйте теги H1 страницы с разбивкой на страницы.
- Добавляйте полезный текст на странице на корневую страницу, но не страницы с разбивкой на страницы.
- Добавьте изображение категории с оптимизированным именем файла и тегом alt на корневую страницу, но не страницы с разбивкой на страницы.
Не включайте страницы с разбивкой на страницы в XML-файлы Sitemap Хотя URL-адреса
с разбивкой на страницы технически индексируются, они не являются приоритетом SEO для траты бюджета на сканирование.
Таким образом, они не относятся к вашей XML-карте сайта.
Обработка параметров нумерации страниц в Google Search Console Если
If you have a choice, run pagination via a parameter rather than a static URL. Например:
example.com/category?page=2 over example.com/category/page-2
Хотя нет никакого преимущества использования одного перед другим для ранжирования или сканирования, исследования показали, что робот Googlebot, похоже, угадывает шаблоны URL-адресов на основе динамических URL-адресов. Таким образом, увеличивается вероятность быстрого обнаружения.
С другой стороны, это потенциально может вызвать ловушки сканирования, если сайт отображает пустые страницы для догадок, которые не являются частью текущей серии с разбивкой на страницы.
Например, предположим, что серия содержит четыре страницы.
URL-адреса с содержимым останавливаются на www.example.com/category?page=4
Если Google угадывает www.example.com/category?page=7 и загружается живая, но пустая страница, бот тратит впустую бюджет сканирования и потенциально теряется в бесконечном количестве страниц.
Убедитесь, что код состояния HTTP 404 отправлен для всех страниц с разбивкой на страницы, которые не являются частью текущей серии.
Еще одним преимуществом подхода, основанного на параметрах, является возможность настроить параметр в Google Search Console на «Разбиение на страницы» и в любое время изменить сигнал Google для сканирования «Каждый URL» или «Нет URL-адресов» в зависимости от того, как вы хотите использовать свой бюджет сканирования. Разработчик не нужен!
Никогда не сопоставляйте содержимое страницы с разбивкой на страницы с идентификаторами фрагментов (#), поскольку оно не сканируется и не индексируется и, как таковое, не подходит для поисковых систем.
Неправильно понятые, устаревшие или просто неправильные SEO-решения для контента
с разбивкой на страницы ничего не делают Google считает, что робот Googlebot достаточно умен, чтобы найти следующую страницу по ссылкам, поэтому ему не

нужен какой-либо явный сигнал.
Сообщение для SEO, по сути, заключается в том, чтобы обрабатывать нумерацию страниц, ничего не делая.
Хотя в этом утверждении есть доля правды, ничего не делая, вы играете в азартные игры со своим SEO.
Многие сайты видели, как Google выбирает страницу с разбивкой на страницы для ранжирования по корневой странице по поисковому запросу.
Всегда полезно давать четкие указания сканерам о том, как вы хотите, чтобы они индексировали и отображали ваш контент.
Канонизировать на страницу «Просмотреть все» Страница «Просмотреть
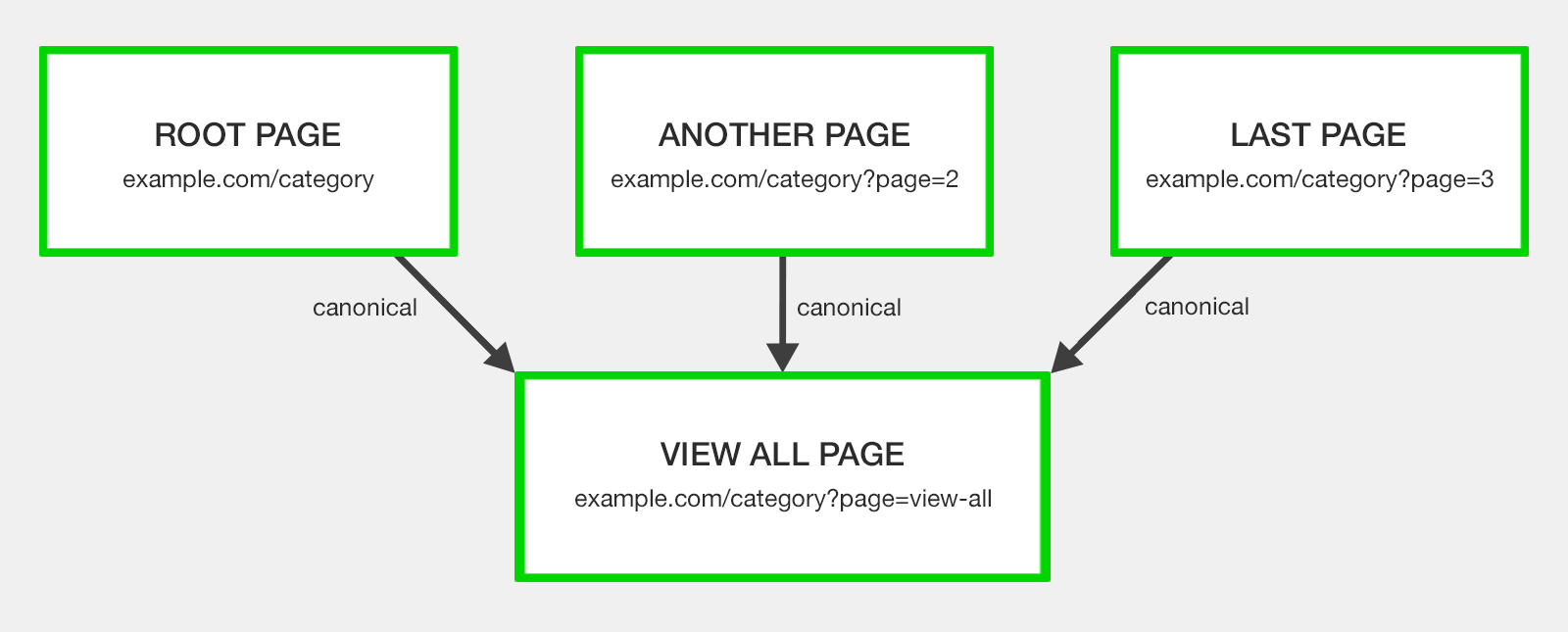
все» была задумана так, чтобы содержать все содержимое страницы компонента на одном URL-адресе.
Со всеми страницами с разбивкой на страницы, имеющими rel = "canonical" для страницы "Просмотреть все" для консолидации сигналов ранжирования.
Аргумент здесь заключается в том, что поисковики предпочитают просматривать всю статью или список категорий на одной странице, если она быстро загружается и проста в навигации.
Концепция заключалась в том, что если у вашей серии с разбивкой на страницы есть альтернативная версия «Просмотреть все», которая предлагает лучший пользовательский опыт, поисковые системы будут отдавать предпочтение этой странице для включения в результаты поиска, а не соответствующей странице сегмента цепочки нумерации страниц.
В связи с этим возникает вопрос: почему у вас вообще есть страницы с разбивкой на страницы?
Давайте сделаем это просто.
Если вы можете предоставить свой контент по одному URL-адресу, предлагая при этом хороший пользовательский интерфейс, нет необходимости в нумерации страниц или версии «Просмотреть все».
Если вы не можете, например, страница категории с тысячами товаров будет смехотворно большой и слишком долго загружаться, то разбивайте на страницы. «Просмотреть все» — не лучший вариант, так как он не обеспечит хорошего пользовательского опыта.
Использование как rel = "next" / "prev", так и версии View All не дает четкого мандата поисковым системам и приведет к путанице сканеров.
Не делайте этого.
Канонизировать на первую страницу Распространенной ошибкой является указание rel="canonical" из всех результатов с разбивкой на страницы на корневую страницу

серии.
Некоторые плохо информированные SEO-специалисты предлагают это как способ консолидировать полномочия по набору страниц на корневой странице, но это дезинформировано.
Неправильная канонизация корневой страницы рискует ввести в заблуждение поисковые системы, заставив их думать, что у вас есть только одна страница результатов.
В этом случае робот Googlebot не будет индексировать страницы, которые появляются дальше по цепочке, и не будет подтверждать сигналы к контенту, связанному с этими страницами.
Вы не хотите, чтобы ваши страницы с подробным контентом выпадали из индекса из-за плохой обработки страниц.
Каждая страница в серии с разбивкой на страницы должна иметь каноническую ссылку на себя, если только вы не используете страницу «Просмотреть все».
Неправильно используйте rel=canonical, и, скорее всего, робот Googlebot просто проигнорирует ваш сигнал.

Классическим методом решения проблем нумерации страниц был тег noindex robots, чтобы предотвратить индексацию контента с разбивкой на страницы поисковыми системами.
Использование исключительно тега noindex для обработки страниц приведет к тому, что любые сигналы ранжирования со страниц компонентов будут игнорироваться.
Однако более серьезная проблема с этим методом заключается в том, что долгосрочный noindex на странице в конечном итоге приведет к тому, что Google не будет переходить по ссылкам на этой странице.
Это может привести к удалению из индекса контента, связанного со страницами с разбивкой на страницы.
Нумерация страниц и бесконечная прокрутка или загрузка большего

количества страниц Более новая форма обработки страниц заключается в следующем:
- Бесконечная прокрутка, при которой содержимое предварительно извлекается и добавляется непосредственно на текущую страницу пользователя при прокрутке вниз.
- Загрузить больше, где контент отображается при нажатии кнопки «Просмотреть больше».
Эти подходы ценятся пользователями, но Googlebot? Не так уж и много.
Робот Googlebot не имитирует такое поведение, как прокрутка страницы вниз или щелчок для загрузки дополнительных данных. Это означает, что без посторонней помощи поисковые системы не могут эффективно сканировать весь ваш контент.
Чтобы быть оптимизированным для SEO, преобразуйте бесконечную прокрутку или загружайте больше страниц в эквивалентную серию с разбивкой на страницы, основанную на сканируемых якорных ссылках с атрибутами href, которая доступна даже при отключенном JavaScript.
Когда пользователь прокручивает страницу или щелкает, используйте JavaScript, чтобы адаптировать URL-адрес в адресной строке к странице с разбивкой на страницы.
Кроме того, реализуйте pushState для любого действия пользователя, которое напоминает щелчок или активное перелистывание страницы. Вы можете проверить эту функциональность в демонстрации, созданной Джоном Мюллером.
По сути, вы по-прежнему применяете лучшие практики SEO, рекомендованные выше, вы просто добавляете дополнительные функции пользовательского интерфейса сверху.
Некоторые
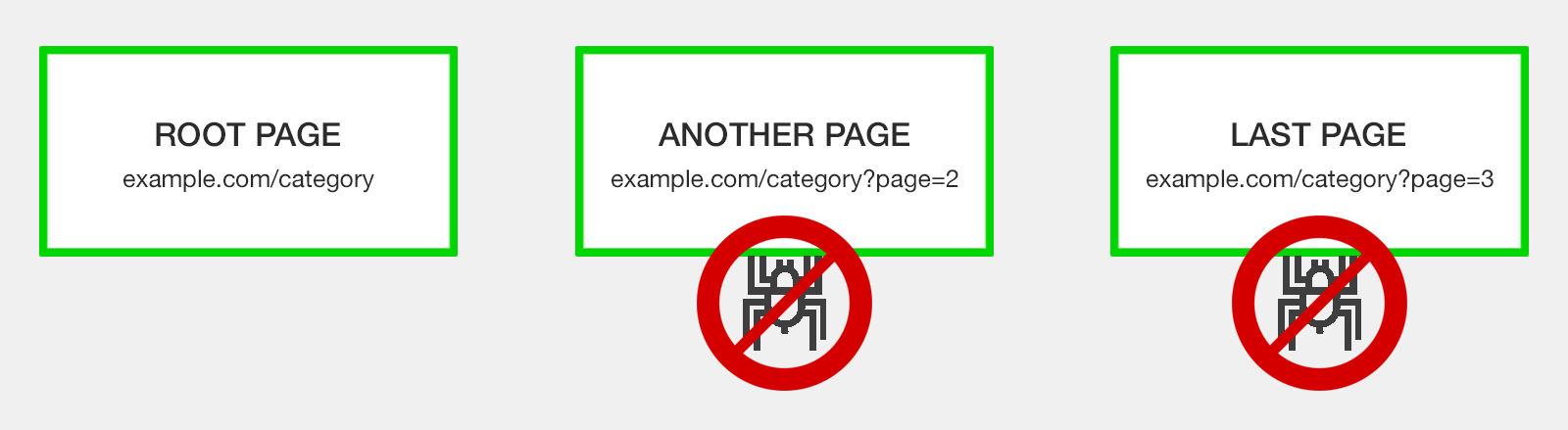
специалисты по SEO рекомендуют вообще избегать проблемы обработки страниц с разбивкой на страницы, просто заблокировав Google от сканирования URL-адресов с разбивкой на страницы.
В таком случае вы хотели бы иметь хорошо оптимизированные XML-карты сайта , чтобы страницы, связанные с пагинацией, имели шанс быть проиндексированными.
Существует три способа блокировки сканеров:
- Грязный способ: добавьте nofollow ко всем ссылкам, которые указывают на страницы с разбивкой на страницы.
- Более чистый способ: используйте роботов.txt запретите.
- Способ не нужен разработчику: установите для параметра страницы с разбивкой на страницы значение «Разбиение на страницы» и чтобы Google сканировал «Без URL-адресов» в Google Search Console.
Используя один из этих методов, чтобы отговорить поисковые системы от сканирования URL-адресов с разбивкой на страницы, вы:
- Запретить поисковым системам распознавать сигналы ранжирования страниц с разбивкой на страницы.
- Предотвратите передачу внутреннего ссылочного капитала со страниц с разбивкой на страницы вниз по целевым страницам контента.
- Помешайте Google обнаруживать страницы с целевым контентом.
Очевидным плюсом является то, что вы экономите на бюджете сканирования.
Здесь нет четкого правильного или неправильного. Вам нужно решить, что является приоритетом для вашего сайта.
Лично, если бы я расставлял приоритеты в бюджете сканирования, я бы сделал это, используя обработку страниц в Google Search Console, поскольку она обладает оптимальной гибкостью, чтобы изменить ваше мнение.
Отслеживание влияния пагинации
на ключевые показатели эффективности Итак, теперь вы знаете, что делать, как вы отслеживаете эффект от оптимизации обработки страниц на страницы?
Во-первых, соберите эталонные данные, чтобы понять, как ваша текущая обработка страниц влияет на SEO.
Источниками ключевых показателей эффективности могут быть:
- Файлы журналов сервера для количества обходов страниц с разбивкой на страницы.
- Site: оператор поиска (например, site:example.com inurl:page), чтобы понять, сколько страниц с разбивкой на страницы проиндексировал Google.
- Консоль поиска Google Отчет Search Analytics фильтруется по страницам, содержащим нумерацию страниц, чтобы понять количество показов.
- Отчет о целевой странице Google Analytics отфильтрован по URL-адресам с разбивкой на страницы, чтобы понять поведение на сайте.
Если вы видите проблему, из-за которой поисковые системы сканируют разбиение вашего сайта на страницы для доступа к вашему контенту, вы можете изменить ссылки на страницы.
После того, как вы запустили свою передовую обработку страниц на страницы, вернитесь к этим источникам данных, чтобы оценить успех ваших усилий.
Кредиты изображений
Рекомендуемое изображение: Пауло Бобита
Изображения / скриншоты в посте: созданные/сделанные автором


