Strona paginacji jest sprytnym zmiennokształtnym. Jest używany w kontekstach od wyświetlania elementów na stronach kategorii, przez archiwa artykułów, pokazy slajdów z galerii i wątki na forum.
Dla specjalistów SEO nie chodzi o to, czy będziesz miał do czynienia z paginacją, ale o to, kiedy.
W pewnym momencie wzrostu witryny muszą dzielić treści na szereg stron składowych w celu zapewnienia komfortu użytkownika (UX).
Naszym zadaniem jest pomoc wyszukiwarkom w indeksowaniu i zrozumieniu relacji między tymi adresami URL, aby indeksowały najbardziej odpowiednią stronę.
Z biegiem czasu najlepsze praktyki SEO w zakresie obsługi paginacji ewoluowały. Po drodze wiele mitów przedstawiało się jako fakty. Ale już nie.
Ten artykuł:
- Obalenie mitów na temat tego, jak paginacja szkodzi SEO.
- Przedstaw optymalny sposób zarządzania paginacją.
- Przejrzyj źle zrozumiane lub niewłaściwe metody obsługi paginacji.
- Zbadaj, jak śledzić wpływ wskaźnika KPI na paginację.
Jak paginacja może zaszkodzić SEO Prawdopodobnie czytałeś, że paginacja jest zła dla SEO
.
Jednak w większości przypadków wynika to z braku prawidłowej obsługi paginacji, a nie z istnienia samej paginacji.
Spójrzmy na rzekome zło paginacji i jak przezwyciężyć problemy SEO, które może spowodować.
Paginacja powoduje zduplikowanie treści
Popraw, jeśli paginacja została nieprawidłowo zaimplementowana, na przykład strona "Wyświetl wszystko" i strony podzielone na strony bez poprawnego atrybutu rel=canonical lub jeśli oprócz strony głównej utworzono page=1.
Nieprawidłowy, gdy masz przyjazną dla SEO paginację. Nawet jeśli tagi H1 i metatagi są takie same, rzeczywista zawartość strony jest różna. Więc to nie jest duplikacja.
Tak, w porządku. Przydatne jest uzyskanie informacji zwrotnej na temat zduplikowanych tytułów i opisów, jeśli przypadkowo użyjesz ich na całkowicie oddzielnych stronach, ale w przypadku serii podzielonych na strony jest to normalne i oczekuje się, że użyje tego samego.
— 🍌 John 🍌 (@JohnMu) 13 marca 2018
r. Paginacja tworzy cienką treść
Popraw, jeśli artykuł lub galeria zdjęć została podzielona na wiele stron (w celu zwiększenia przychodów z reklam poprzez zwiększenie liczby odsłon), pozostawiając zbyt mało treści na każdej stronie.
Niepoprawne, gdy stawiasz pragnienia użytkownika, aby łatwo konsumować Twoje treści, ponad przychody z banerów reklamowych lub sztucznie zawyżone odsłony. Umieść przyjazną dla UX ilość treści na każdej stronie.
Paginacja rozcieńcza sygnały
rankingowepoprawnie. Paginacja powoduje, że wewnętrzna sprawiedliwość linków i inne sygnały rankingowe, takie jak linki zwrotne i udziały społecznościowe, są dzielone na różne strony.
Można jednak zminimalizować, stosując paginację tylko w przypadkach, gdy podejście oparte na zawartości pojedynczej strony spowodowałoby słabe wrażenia użytkownika (na przykład strony kategorii e-commerce). I na takich stronach, dodając jak najwięcej elementów, bez spowalniania strony do zauważalnego poziomu, aby zmniejszyć liczbę stron podzielonych na strony.
Podział na strony korzysta z opcjiIndeksuj budżet poprawny, jeśli zezwalasz Google na indeksowanie stron podzielonych na
strony. I są przypadki, w których chciałbyś wykorzystać ten budżet.
Na przykład Googlebot może przechodzić przez adresy URL podzielone na strony, by docierać do stron z głębszą treścią.
Często niepoprawne, gdy ustawisz obsługę parametrów paginacji w Google Search Console na "Nie indeksuj" lub ustawisz roboty.txt nie zezwalaj, jeśli chcesz zaoszczędzić budżet indeksowania na ważniejsze strony.
Zarządzanie paginacją zgodnie z najlepszymi praktykami SEO Użyj indeksowalnych linków
kotwicy Aby wyszukiwarki mogły skutecznie indeksować strony podzielone na strony, witryna musi zawierać linki kotwic z atrybutami

href do tych adresów URL podzielonych na strony.
Upewnij się, że Twoja witryna używa <a href="twój-url-tutaj> do tworzenia wewnętrznych linków do stron podzielonych na strony. Nie ładuj linków kotwiczących podzielonych na strony ani atrybutu href za pomocą JavaScript.
Ponadto należy wskazać relację między adresami URL komponentów w serii podzielonej na strony za pomocą atrybutów
rel="next" i rel="prev".Tak, nawet po niesławnym tweecie Google, że w ogóle nie używają już tych atrybutów linków.
Wiosenne porządki!
Oceniając nasze sygnały indeksujące, zdecydowaliśmy się wycofać rel=prev/next.
Badania pokazują, że użytkownicy uwielbiają treści jednostronicowe, dążą do tego, gdy to możliwe, ale wieloczęściowe są również dobre dla wyszukiwarki Google. Wiedz i rób to, co jest najlepsze dla *Twoich* użytkowników! #springiscoming .twitter.com/hCODPoKgKp— Google Webmasters (@googlewmc) 21 marca 2019 r.
Wkrótce potem Ilya Grigorik wyjaśnił, że rel="next" / "prev" może być nadal cenne.
Nie, użyj paginacji. Pozwólcie, że to przeformułuję. Googlebot jest wystarczająco sprytny, aby znaleźć następną stronę, patrząc na linki na stronie, nie potrzebujemy wyraźnego sygnału "poprzedni, następny". I tak, istnieją inne świetne powody (np. A11Y), dla których możesz chcieć lub potrzebować dodać je nadal.
— Ilya Grigorik (@igrigorik) 22 marca 2019
Google nie jest jedyną wyszukiwarką w mieście. Oto podejście Bing do tego problemu.
Używamy rel prev/next (jak większość znaczników) jako wskazówek do odkrywania stron i zrozumienia struktury witryny. W tym momencie nie scalamy stron w indeksie na ich podstawie i nie używamy prev/next w modelu rankingu.
https://t.co/ZwbSZkn3Jf— Frédéric Dubut (@CoperniX) 21 marca 2019
r. Uzupełnij rel="next" / "prev" linkiem rel="canonical". Tak więc /category?page=4 powinno rel="canonical" do /category?page=4.
Jest to właściwe, ponieważ paginacja zmienia zawartość strony, podobnie jak główna kopia tej strony.
Jeśli adres URL zawiera dodatkowe parametry, uwzględnij je w linkach rel="prev" / "next", ale nie umieszczaj ich w rel="canonical".
Na przykład:
<link rel="next" href="https://www.example.com/category?page=2&order=newest" />
<link rel="canonical" href="https://www.example.com/category?page=2" />
Spowoduje to wyraźne powiązanie między stronami i zapobiegnie potencjalnemu powielaniu treści.
Typowe błędy, których należy unikać:
- Umieszczenie atrybutów linku
<body>w treści. Są one obsługiwane tylko przez wyszukiwarki w<head>sekcji kodu HTML. - Dodanie linku rel="prev" do pierwszej strony (czyli strony głównej) w serii lub linku rel="next" do ostatniej. W przypadku wszystkich innych stron w łańcuchu powinny być obecne oba atrybuty linku.
- Uważaj na kanoniczny adres URL strony głównej. Szanse są na ?page=2, rel=prev powinien linkować do kanonicznego, a nie ?page=1.
Kod <head> czterostronicowej serii będzie wyglądał mniej więcej tak:
- Jeden znacznik paginacji na stronie głównej, wskazujący następną stronę serii.
<link rel="next" href="https://www.example.com/category?page=2″><link rel="canonical" href="https://www.example.com/category">
<link rel="prev" href="https://www.example.com/category"><link rel="next" href="https://www.example.com/category?page=3″><link rel="canonical" href="https://www.example.com/category?page=2">
<link rel="prev" href="https://www.example.com/category?page=2″><link rel="next" href="https://www.example.com/category?page=4″><link rel="canonical" href="https://www.example.com/category?page=3">
<link rel="prev" href="https://www.example.com/category?page=3"><link rel="canonical" href="https://www.example.com/category?page=4">
Modyfikowanie stron
podzielonych na strony elementów na stronie John Mueller skomentował: "Nie traktujemy paginacji inaczej. Traktujemy je jak normalne strony".
Oznacza to, że strony podzielone na strony nie są rozpoznawane przez Google jako seria stron skonsolidowanych w jeden fragment treści, jak wcześniej zalecano. Każda strona podzielona na strony kwalifikuje się do konkurowania ze stroną główną o ranking.
Aby zachęcić Google do zwrócenia strony głównej w SERP i zapobiec ostrzeżeniom "Zduplikowane metaopisy" lub "Zduplikowane tagi tytułu" w Google Search Console, dokonaj łatwej modyfikacji kodu.
Jeśli strona główna ma formułę:Kolejne strony podzielone na strony mogą mieć formułę:


Te tytuły stron URL i opis meta są celowo nieoptymalne, aby zniechęcić Google do wyświetlania tych wyników, a nie strony głównej.
Jeśli nawet przy takich modyfikacjach strony podzielone na strony są w rankingu SERP, wypróbuj inne tradycyjne taktyki SEO na stronie, takie jak:
- Usuń optymalizację tagów H1 strony stronicowanej.
- Dodaj przydatny tekst na stronie głównej, ale nie strony podzielone na strony.
- Dodaj obraz kategorii ze zoptymalizowaną nazwą pliku i tagiem alt do strony głównej, ale nie do stron podzielonych na strony.
Nie uwzględniaj stron podzielonych na strony w mapach
witryn XML Chociaż adresy URL podzielone na strony są technicznie indeksowalne, nie są priorytetem SEO, na który należy przeznaczyć budżet na indeksowanie.
W związku z tym nie należą one do mapy witryny XML.
Obsługa parametrów paginacji w Google Search Console
If you have a choice, run pagination via a parameter rather than a static URL. Na przykład:
example.com/category?page=2 over example.com/category/page-2
Chociaż nie ma przewagi nad używaniem jednego z nich do celów rankingowych lub indeksowania, badania wykazały, że Googlebot wydaje się odgadywać wzorce adresów URL na podstawie dynamicznych adresów URL. W ten sposób zwiększa się prawdopodobieństwo szybkiego odkrycia.
Z drugiej strony może to potencjalnie powodować pułapki indeksowania, jeśli witryna renderuje puste strony dla domysłów, które nie są częścią bieżącej serii stronicowanej.
Załóżmy na przykład, że seria zawiera cztery strony.
Adresy URL z treścią zatrzymują się na www.example.com/category?page=4
Jeśli Google zgadnie, www.example.com/category?page=7 i załadowana jest aktywna, ale pusta strona, bot marnuje budżet indeksowania i potencjalnie gubi się w nieskończonej liczbie stron.
Upewnij się, że kod stanu HTTP 404 został wysłany dla wszystkich stron podzielonych na strony, które nie należą do bieżącej serii.
Kolejną zaletą podejścia parametrycznego jest możliwość skonfigurowania parametru w Google Search Console na "Paginates" i w dowolnym momencie zmienić sygnał do Google, aby zindeksować "Każdy adres URL" lub "Brak adresów URL", w zależności od tego, jak chcesz wykorzystać budżet indeksowania. Programista nie jest potrzebny!
Nigdy nie mapuj zawartości strony stronicowanej na identyfikatory fragmentów (#), ponieważ nie można jej indeksować ani indeksować i jako taka nie jest przyjazna dla wyszukiwarek.
Źle zrozumiane, przestarzałe lub po prostu złe rozwiązania SEO do podzielonej na strony treści
nic nie robią Google

uważa, że Googlebot jest wystarczająco inteligentny, aby znaleźć następną stronę za pomocą linków, więc nie potrzebuje żadnego wyraźnego sygnału.
Wiadomość do SEO jest zasadniczo taka, aby poradzić sobie z paginacją, nie robiąc nic.
Chociaż w tym stwierdzeniu jest rdzeń prawdy, nic nie robiąc, ryzykujesz swoim SEO.
W wielu witrynach Google wybrał stronę podzieloną na strony, aby umieścić ją na stronie głównej dla zapytania.
Zawsze warto udzielać robotom indeksującym jasnych wskazówek, w jaki sposób mają indeksować i wyświetlać treści.
Kanoniczna do strony
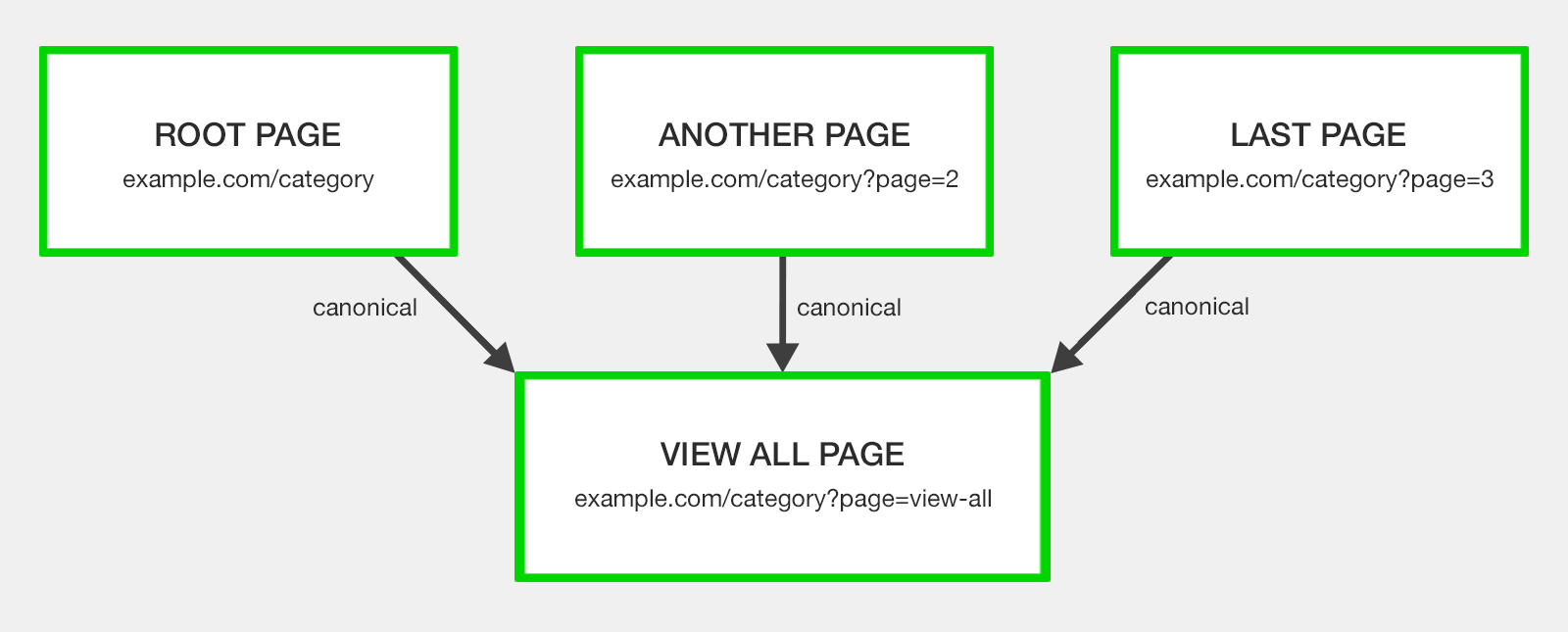
Wyświetl wszystkie Strona Wyświetl wszystko została zaprojektowana tak, aby zawierała całą zawartość strony składowej w jednym adresie URL.
Wszystkie strony podzielone na strony mają atrybut rel="canonical" na stronie Wyświetl wszystkie, aby skonsolidować sygnały rankingu.
Argumentem jest to, że wyszukiwarki wolą przeglądać cały artykuł lub listę elementów kategorii na jednej stronie, o ile jest to szybkie ładowanie i łatwa nawigacja.
Koncepcja polegała na tym, że jeśli seria podzielona na strony ma alternatywną wersję Wyświetl wszystko, która oferuje lepsze wrażenia użytkownika, wyszukiwarki będą faworyzować tę stronę do uwzględnienia w wynikach wyszukiwania, w przeciwieństwie do odpowiedniej strony segmentu łańcucha paginacji.
Co rodzi pytanie – dlaczego w ogóle masz strony podzielone na strony?
Uczyńmy to prostym.
Jeśli możesz dostarczyć zawartość pod jednym adresem URL, oferując jednocześnie wygodę użytkownika, nie ma potrzeby paginacji ani wersji Wyświetl wszystko.
Jeśli nie możesz, na przykład, strona kategorii z tysiącami produktów byłaby absurdalnie duża i ładowanie trwałoby zbyt długo, a następnie paginacja. Wyświetl wszystko nie jest najlepszą opcją, ponieważ nie zapewni dobrego doświadczenia użytkownika.
Używanie zarówno wersji rel="next" / "prev", jak i View All nie daje wyraźnego mandatu wyszukiwarkom i spowoduje zdezorientowanie robotów.
Nie rób tego.
Kanonizacja na pierwszej stronie

Częstym błędem jest wskazywanie atrybutu rel="canonical" ze wszystkich wyników podzielonych na strony na stronę główną serii.
Niektórzy źle poinformowani SEO sugerują, że jest to sposób na konsolidację autorytetu w całym zestawie stron do strony głównej, ale jest to błędne informacje.
Nieprawidłowa kanonizacja na stronie głównej grozi błędnym przekierowaniem wyszukiwarek do myślenia, że masz tylko jedną stronę wyników.
Googlebot nie indeksuje stron, które pojawiają się dalej w łańcuchu, ani nie potwierdza sygnałów do treści, do których prowadzą linki z tych stron.
Nie chcesz, aby strony ze szczegółową treścią wypadały z indeksu z powodu złej obsługi paginacji.
Każda strona w serii podzielonej na strony powinna mieć kanoniczne odniesienia do siebie, chyba że używasz strony Wyświetl wszystkie.
Użyj atrybutu rel=canonical niepoprawnie, a istnieje duże prawdopodobieństwo, że Googlebot po prostu zignoruje Twój sygnał.
Noindex Paginated Pages

Klasyczną metodą rozwiązywania problemów z paginacją był robots noindex tag, który zapobiegał indeksowaniu treści podzielonych na strony przez wyszukiwarki.
Poleganie wyłącznie na tagu noindex do obsługi paginacji spowoduje zignorowanie wszelkich sygnałów rankingowych ze stron składowych.
Jednak większym problemem związanym z tą metodą jest to, że długoterminowy noindex na stronie ostatecznie doprowadzi Google do nofollow linków na tej stronie.
Może to spowodować usunięcie z indeksu zawartości, do której prowadzą łącza ze stron podzielonych na strony.
Paginacja i nieskończone przewijanie lub ładowanie Więcej

Nowszą formą obsługi paginacji są:
- Nieskończone przewijanie, w którym zawartość jest wstępnie pobierana i dodawana bezpośrednio do bieżącej strony użytkownika podczas przewijania w dół.
- Załaduj więcej, gdzie treść jest renderowana po kliknięciu przycisku "zobacz więcej".
Takie podejście jest doceniane przez użytkowników, ale Googlebot? Nie tak bardzo.
Googlebot nie emuluje takich zachowań, jak przewijanie do dołu strony czy klikanie, by wczytać więcej. Oznacza to, że bez pomocy wyszukiwarki nie mogą skutecznie indeksować wszystkich treści.
Aby być przyjaznym dla SEO, przekonwertuj nieskończone przewijanie lub załaduj więcej strony na równoważną serię podzieloną na strony, opartą na indeksowalnych linkach kotwiczących z atrybutami href, które są dostępne nawet przy wyłączonym JavaScript.
Gdy użytkownik przewija lub klika, użyj JavaScript, aby dostosować adres URL na pasku adresu do strony komponentu stronicowania.
Ponadto zaimplementuj pushState dla każdej akcji użytkownika, która przypomina kliknięcie lub aktywne obracanie strony. Możesz sprawdzić tę funkcjonalność w wersji demonstracyjnej stworzonej przez Johna Muellera.
Zasadniczo nadal wdrażasz najlepsze praktyki SEO zalecane powyżej, po prostu dodajesz dodatkową funkcjonalność doświadczenia użytkownika na górze.
Odradzaj lub blokuj indeksowanie stron Niektórzy specjaliści SEO zalecają całkowite unikanie problemu z obsługą paginacji, po prostu blokując Google przed indeksowaniem
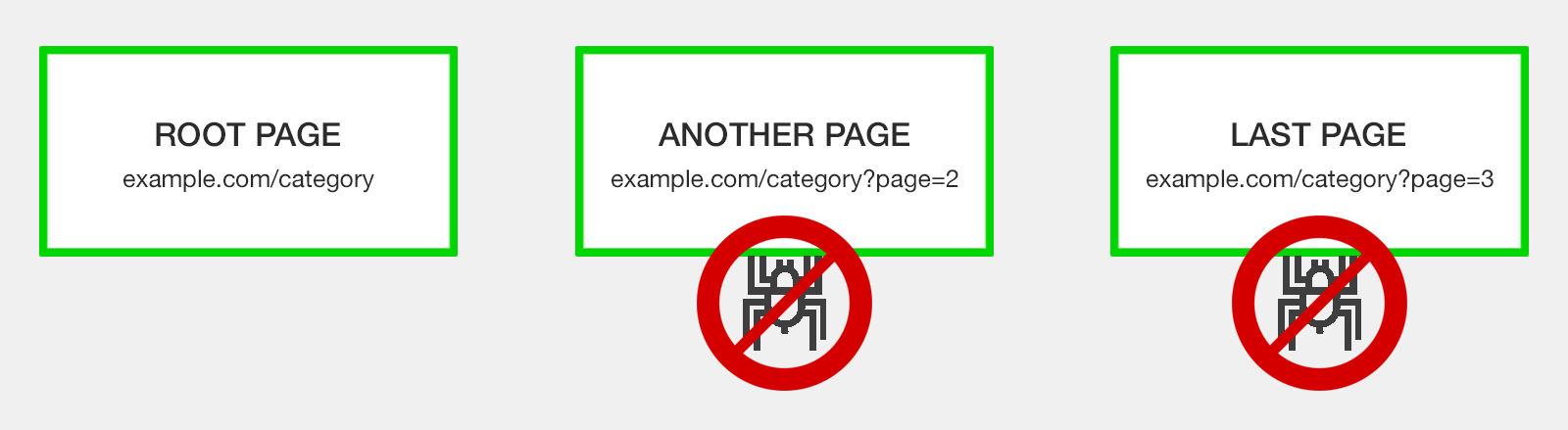
adresów URL podzielonych na strony.
W takim przypadku potrzebujesz dobrze zoptymalizowanych map witryn XML , aby strony połączone za pomocą paginacji miały szansę na indeksowanie.
Istnieją trzy sposoby blokowania robotów:
- Niechlujny sposób: Dodaj nofollow do wszystkich linków prowadzących do stron podzielonych na strony.
- Czystszy sposób: Użyj robotów.txt nie zezwalaj.
- Sposób niepotrzebny deweloper: ustaw parametr strony stronicowanej na "Paginates", a Google indeksuje "Brak adresów URL" w Google Search Console.
Korzystając z jednej z tych metod, aby zniechęcić wyszukiwarki do indeksowania adresów URL podzielonych na strony, możesz:
- Zatrzymaj wyszukiwarki przed rozpoznawaniem sygnałów rankingowych stron podzielonych na strony.
- Zapobiegaj przekazywaniu wewnętrznej równości linków ze stron podzielonych na strony do docelowych stron zawartości.
- Utrudnianie Google odkrywania docelowych stron z treścią.
Oczywistym plusem jest to, że oszczędzasz na budżecie indeksowania.
Nie ma tu wyraźnego dobra lub zła. Musisz zdecydować, co jest priorytetem dla Twojej witryny.
Osobiście, gdybym miał nadać priorytet budżetowi indeksowania, zrobiłbym to, korzystając z obsługi paginacji w Google Search Console, ponieważ ma optymalną elastyczność, aby zmienić zdanie.
Śledzenie wpływu KPI na paginację
Skoro już wiesz, co robić, jak śledzić efekt obsługi paginacji optymalizacji?
Po pierwsze, zbierz dane porównawcze, aby zrozumieć, w jaki sposób bieżąca obsługa paginacji wpływa na SEO.
Źródła wskaźników KPI mogą obejmować:
- Pliki dziennika serwera dla liczby przeszukiwanych stron stron.
- Operator: operator wyszukiwania (na przykład site:example.com inurl: page), by dowiedzieć się, ile stron podzielonych na strony zindeksowało Google.
- Google Search Console Raport Analityka wyszukiwania filtrowany według stron zawierających podział na strony, aby poznać liczbę wyświetleń.
- Raport strony docelowej Google Analytics filtrowany według adresów URL podzielonych na strony, by poznać zachowanie w witrynie.
Jeśli zauważysz problem z indeksowaniem witryny przez wyszukiwarki w celu dotarcia do Twoich treści, możesz zmienić linki stronicowania.
Po uruchomieniu obsługi stronicowania najlepszych praktyk należy ponownie zapoznać się z tymi źródłami danych, aby zmierzyć sukces swoich wysiłków.
Kredyty obrazu
Wyróżniony obraz: Paulo Bobita
Obrazy / zrzuty ekranu: Stworzone / zrobione przez autora


